
Pracując nad systemami opartymi o mikrousługi bardzo mocno skupiamy się nad tym, aby w ogóle działały. Każdy kto raz dotknął takiego systemu i spędził trochę czasu na rozwoju takowego, wie dokładnie, że tutaj… tutaj nawet nikt o darmowym obiedzie nie wspominał. Dostajemy od razu na twarz całkiem spory zbiór spraw, których trzeba pilnować i monitorować, nie to co stare dobre monolity. Patrzymy na service discovery, circuit breakery, skalowanie horyzontalne i wszystkie inne rzeczy, którymi uraczył nas Netflix, a nawet więcej. Nikt nie ma czasu na to, aby patrzeć na szybkość, niech to wszystko narazie działa.
Jeśli jesteśmy w bardziej „świadomym” miejscu i tworzymy coś więcej niż CMSa, zapewne od początku śledzimy wydajność naszej aplikacji, czas spędzony w mikrousługach i statystyki; mamy zdefiniowane SLA (Service Level Agreement) i robimy nawet całkiem przemyślane konstrukcje w naszych mikrousługach. Staramy się drobiazgowo zamodelować domenę, aby odzwierciedlała język biznesowy i była jednocześnie czysta jakby sam „wujek” ją pisał. Po czym… wszystko pakujemy w Springa, bo w końcu Netflix; poza tym REST działa i kocha go każdy (razem z jsonem). I nie zrozummy się źle, doskonale, że kształtujemy aplikację w przemyślany sposób i nie ma nic złego w powyższych technologiach. One są dobre i sprawdzone i dla prawie wszystkich przypadków sprawdzą się świetnie.
Czasami jednak przychodzą momenty, że poszukujemy tej prędkości w dużo większym stopniu, niż standard to definiuje. Kiedy już dopracowaliśmy każdą z mikrousług, do tego stopnia że więcej z jvma nie wyciśniemy, bo wyczerpaliśmy już pomysły na bardziej wydajne przetwarzanie w ramach komponentu, czas zwrócić naszą uwagę w innym kierunku i tam próbować naszych sił. Czasami, jeśli nasza aplikacja jest mocno rozproszona, medium, po którym poruszają się nasze wiadomości, może okazać się tym kierunkiem gdzie uda się „urwać” parę cennych milisekund, a może nawet całą sekundę.
Gra warta świeczki
Nikt nie lubi grać w ciemno, więc podstawowym zadaniem jakie powinniśmy postawić przed sobą, nim zabierzemy się za optymalizację, ba… nim w ogóle o niej pomyślimy powinna być wiedza. Musimy wiedzieć, i na tej podstawie wyciągać wnioski, że optymalizacja to jest to co uratuje naszą aplikację. Sprawi, że trafi na piedestał „tych” aplikacji i znowu trafi na okładkę TechCruncha, zaraz obok uberów i snapczatów. Skąd mamy natomiast wiedzieć?
Mierzyć, mierzyć i jeszcze raz mierzyć. Nigdy nie działać na ślepo.
https://niezawodnykod.pl/2021/01/04/dlaczego-disruptor-jest-szybki/
Nie ma rady, w takim razie zaprzęgamy Grafanę do roboty i sprawdzamy jak zachowuje się nasza aplikacja.
W całym podejściu nieco pomijam i trywializuję przetwarzanie samych wiadomości, które znacząco może spowolnić funkcjonowanie systemu. Zależy mi natomiast, aby w miarę dobrze odzwierciedlić możliwości jakie oferuje medium, którego używamy. Czy w prawdziwym życiu nasze komponenty będą w stanie w pełni je wykorzystać, to już zupełnie inny temat.
Dla naszych celów użyjemy dość trywialnej konstrukcji mającej zaledwie dwa komponenty, jeden publikujący oraz jeden konsumujący żądania. Pierwszy komponent, TrafficGenerator, to inicjator całego ruchu, generujący proste wiadomości:
...
public TrafficGenerator(ExecutorService executorService, Producer aProducer, ObjectMapper mapper) {
this.producer = aProducer;
this.mapper = mapper;
executorService.execute(() -> {
for (long count = 0; ; count++) {
Message message = new Message("message-" + count);
String jsonAsString = objectAsString(message);
producer.publish(jsonAsString);
publishedMessageCount.incrementAndGet();
log.debug("Published message: {}", message);
}
});
}
...Za pomocą interfejsu Producer oraz stosownego medium przekazuje je finalnie do odbiorcy TrafficReceiver:
public class TrafficReceiver {
...
public void process(String jsonAsString) {
receivedMessageCount.incrementAndGet();
log.debug("Received message with content: {}.", jsonAsString);
}
...
}Zliczamy zarówno wiadomości wysłane jak i odebrane, aby na tej podstawie obliczać przepustowość naszego systemu.
Jak na Springa przystało, naszym medium będzie protokół HTTP oraz REST. Komunikacja odbywa się poza jvmem, dokładnie tak jak funkcjonowałyby osobne mikrousługi.
public class RestBasedProducer implements Producer {
...
@Override
public void publish(String jsonAsString) {
template.postForObject("http://localhost:4000/api/v1/event", jsonAsString, String.class);
}
}Dla każdego medium musi istnieć stosowny wrapper, które będzie dopasowany do wybranej komunikacji i pozwoli na przekazanie wiadomości do TrafficReceivera. Dla tego przypadku potrzebujemy „wystawić” kontroler z odpowiednim API:
@RestController
@RequestMapping("/api/v1")
public class RestBasedConsumer {
...
@PostMapping("/event")
public String receive(@RequestBody String jsonAsString) {
receiver.process(jsonAsString);
return "";
}
}Uruchamiając cały powyższy zestaw, jesteśmy w stanie nieco prześledzić wydajność, jaki oferują nasz system bazując na komunikacji REST. W prawdziwym życiu, warto pokusić się o możliwie kompleksowe dane, ale na potrzebę tego krótkiego wpisu, przepustowość jest wystarczająca.

Wychodzi na to, że do dyspozycji mamy ok. 640 wiadomości na sekundę. Nie jest to piorunująca wydajność, ale dla niezbyt skomplikowanych systemów, być może jest to wystarczające. Daje nam to też pewien pogląd i baseline. Jeśli nasza aplikacja nie jest jeszcze wyjątkowo popularną aplikacją, może nawet ktoś odważyłby się o produkcyjną wersję. Co jednak gdy musimy obsłużyć nieco więcej żądań?
Wyjście poza REST
W świecie mikrousług, naturalnym wyborem byłoby horyzontalne skalowanie, ale przy tak niskiej przepustowości wiadomości przez komponent, może okazać się to kosztowne, bo ile takich komponentów musiałoby się ukryć za loadbalancerem, aby uzyskać rząd wielkości lepszą przepustowość. Musimy znaleźć alternatywę dla tego rozwiązania.
Możemy na przykład oprzeć się o brokera wiadomości, np stosunkowo znaną i rozpowszechnioną implementację JMS, ArtemisMQ. Na nasze potrzeby, będziemy korzystać z wersji embedded. Wiadomości będą publikowane przez Producera opartego o JmsTemplate:
public class JmsBasedProducer implements Producer {
...
public void publish(String message) {
jmsTemplate.convertAndSend(message);
}
}Wiadomości natomiast będą przekazywane do receivera poprzez komponent JmsBasedConsumer:
public class JmsBasedConsumer {
...
@JmsListener(destination = "${spring.jms.template.default-destination}")
public void receive(String message) {
receiver.process(message);
}
}Możnaby rzec, że poziom skomplikowania delikatnie wzrósł, bo musimy brać pod uwagę (i potencjalnie też utrzymywać) brokera, który będzie umożliwiał przesył wiadomości. Tracimy też trochę elastyczność na rzecz definiowania dla każdej komunikacji odpowiedniej kolejki bądź topicu.
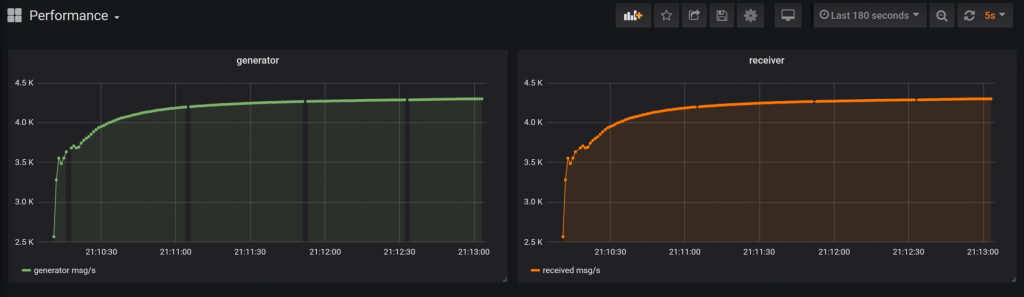
Coś poświęciliśmy, więc siłą rzeczy chcemy coś otrzymać w zamian. Zyskujemy dużo lepszą wydajność na poziomie 4.5k wiadomości. Warto też nadmienić, że funkcjonalnie komponenty nie uległy zmianie, jedynie brzegowe interfejsy nieco zmieniliśmy, aby dopasować nieco publikację oraz odczyt danych z wybranego medium.
Czy da się lepiej?
Trywialne rozwiązania dobrze sprawdzają się w prostych systemach i nie są szczególnie interesujące dla nas jeśli wymagania stawiane przed naszym systemem są dużo bardziej ambitne. W takich momentach trzeba sięgnąć nieco głębiej w czeluścia githuba i szukać rozwiązań dedykowanych. Co rozumiem przez słowo dedykowane w tym kontekście? Chodzi o narzędzia co do zasady niszowe, jak na przykład Disruptor, które rozwiązują bardzo wąski problem, ale robią to niezwykle dobrze. W tym momencie zależy nam na wyjątkowo szybkim transferze wiadomości między komponentami, a narzędziem, które świetnie się wpisuje w takie zastosowanie może być na przykład Aeron.
Aeron to rozwiązanie opierające się o bardzo wydajną komunikację pomiędzy procesami systemowymi (IPC), a w szczególności o protokół UDP z dodatkową wbudowaną gwarancją dostarczenia, której sam protokół nie zapewnia. Zaprojektowane zostało z myślą o zapewnieniu maksymalnej i przewidywalnej wydajności, co powodowało na przykład użycie jednej z lepszych bibliotek do kodowania binarnego, mianowicie SBE (Simple Binary Encoding). Twórcy nie rozdrabniali się na inne, poboczne tematy co pozwoliło na uzyskanie ciekawej alternatywy do komunikacji mikrousług.
Po jednej stronie, mamy implementację naszego Producera, która publikuje wiadomości w ramach struktury oferowanej przez kontekst Aerona.
public class AeronBasedProducer implements Producer, Closeable {
...
public AeronBasedProducer(AeronResultStateLogger aeronResultStateLogger, int streamId, String channel) {
this.aeronResultStateLogger = aeronResultStateLogger;
Aeron.Context context = new Aeron.Context();
aeron = Aeron.connect(context);
publication = aeron.addPublication(channel, streamId);
log.info("Created aeron producer at channel {} with stream {}.", channel, streamId);
}
...
@Override
public void publish(String jsonAsString) {
UnsafeBuffer buffer = new UnsafeBuffer(BufferUtil.allocateDirectAligned(256, 64));
byte[] bytes = jsonAsString.getBytes();
buffer.putBytes(0, bytes);
long result = publication.offer(buffer, 0, bytes.length);
aeronResultStateLogger.describeIfFailedPublication(result);
if (!publication.isConnected()) {
log.info("No active subscribers detected");
}
}
}Po drugiej stronie mamy komponent konsumujący wiadomości i przekazujący je dalej do już wcześniej wspomnianego TrafficReceivera. Cały proces odbywa się w osobnym wątku, gdzie nasłuchując odpowienio skonfigurowaną subskrypcję Aerona, odczytujemy wiadomości i w ramach handlera przekazujemy je dalej.
public class AeronBasedConsumer implements Closeable {
...
public AeronBasedConsumer(ExecutorService executorService, TrafficReceiver aReceiver,
int streamId, String channel) {
this.receiver = aReceiver;
Aeron.Context context = new Aeron.Context();
aeron = Aeron.connect(context);
subscription = aeron.addSubscription(channel, streamId);
log.info("Created aeron consumer at channel {} with stream {}.", channel, streamId);
executorService.execute(consumeFragmentsWhileRunning(subscription));
}
private Runnable consumeFragmentsWhileRunning(Subscription subscription) {
int fragmentLimitCount = 10;
FragmentHandler fragmentHandler = (buffer, offset, length, header) -> {
final byte[] data = new byte[length];
buffer.getBytes(offset, data);
String message = new String(data);
receiver.process(message);
};
final IdleStrategy idleStrategy = new BackoffIdleStrategy(100, 10,
MICROSECONDS.toNanos(1), MICROSECONDS.toNanos(100));
return () -> {
while (running.get()) {
final int fragmentsRead = subscription.poll(fragmentHandler, fragmentLimitCount);
idleStrategy.idle(fragmentsRead);
}
};
}
...
}Kiedy całość już uruchomimy, naszym oczom ukazuje się następujący obraz przetwarzania.
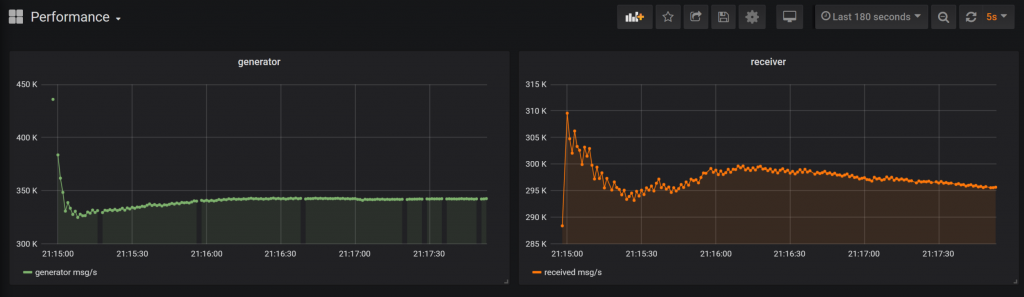
Po odpowiedniej adaptacji naszych podstawowych komponentów, nasza wydajność stabilizuje się w granicach 295k wiadomości. Wcześniejsze wyniki odpowiednio 640 czy też parę tysięcy na sekundę pokazują jak wielka przepaść dzieli te rozwiązania. Nie spędzając aż tak wiele czasu na zupełnej przebudowie naszej aplikacji, poprzez dość precyzyjny wybór narzędzi zdołaliśmy poprawić wydajność naszego systemu o rzędy wielkości. Oczywiście, ile narzędzi tyle wyników i Kafka miała by tutaj również swoje 5 minut, natomiast jeśli zależy nam na najbardziej jaskrawym ekstremum, w pozytywnym znaczeniu tego słowa, to Aeron sprawdzi się najlepiej.
Warto także zaznaczyć, że wszelkie poniższe testy są wykonywane na moim prywatnym laptopie z relatywnie skromnym procesorem Intel Core i7-4720HQ z architekturą Haswell, więc potencjalnie wydajność można przesunąć znacznie dalej używając dostatecznie dopieszczonej maszyny. Trzeba też pamiętać, że wszelka komunikacja mimo wszystko odbywała się w ramach jednej maszyny i mimo, że odbywała się poza jvmem, powyższe wyniki mogą znacząco się różnić jeśli integrowalibyśmy mikrousługi działające na dwóch oddzielnych maszynach.
Słowo na koniec
Wydajność Aerona jest wyjątkowo dobra. Nie ma tutaj cienia wątpliwości. Wybrałem także tę bibliotekę, aby pokazać jak wiele zależy nie tylko od samej mikrousługi, ale i od ekosystemu w jakim funkcjonuje.
Trzeba także pamiętać, że to narzędzie ma swoje miejsce… i nie każda aplikacja jest tym miejscem. Jeśli wymagania i SLA są określone i sensowne, a system radzi sobie z ruchem przyzwoicie to najprawdopodobniej nie ma sensu inwestować w to podejście. Jeśli jednak na dłużące się milisekundy w przetwarzaniu podnosisz brew z niesmakiem, może się okazać, że Aeron okaże się nader przydatny.
Cały projekt, który posłużył jako baza do tego wpisu możesz znaleźć tutaj: https://bitbucket.org/PawelRebisz/aeron-usage/src/master/, więc jeśli chcesz samemu sprawdzić jakie pomiary uzyskasz na swoim komputerze, wszystko znajduje się w tym repozytorium. Znajdziesz tam zarówno skonfigurowaną Grafanę opakowaną w docker-compose jak i TrafficGenerator.